


You built APIs that power your core business logic, handle sensitive data, and serve thousands of requests per second. Now you want to build real-time AI data pipelines, enable AI agents, or create intelligent assistants. A significant challenge exists because LLMs do not act like traditional API clients.
Web apps or mobile clients follow strict request patterns, but LLMs generate dynamic and probabilistic outputs. They create unexpected queries, attempt lateral access escalation, or inadvertently expose credentials through conversational outputs. A single misconfigured endpoint could leak customer data, trigger unauthorized transactions, or allow prompt injection attacks that bypass your entire security layer.
The risk increases because LLM-driven API calls operate at machine speed and often lack human oversight. Traditional API security measures like rate limiting, static input validation, and API keys are insufficient. You need an architecture designed for unpredictability, runtime guardrails that adapt to context, and visibility into every AI-generated request.
This guide walks you through enterprise-grade patterns for securely exposing APIs to LLMs. We cover identity-based access control, zero-trust enforcement, and practical integration examples using APILayer.
Table of Contents
Key Takeaways
Dynamic threats require adaptive defenses: LLMs generate unpredictable requests that bypass traditional API validation, so you need scoped tokens, prompt filtering, and runtime monitoring as non-negotiable security layers.
Authentication hierarchy matters: Replace static API keys with short-lived OAuth2 tokens, role-based scopes, and context-aware permissions that adapt to AI agent behavior patterns.
API gateways become enforcement layers: Centralize request validation, rate limiting, policy checks, and logging through gateways before any LLM request touches backend systems, creating a single chokepoint for security enforcement.
Zero-trust architecture is the baseline: Verify every request regardless of source, segment network access, enforce least-privilege principles, and monitor all LLM-API interactions in real time to catch anomalies before they escalate.
APILayer products enable secure-by-design integration: APILayer marketplace provides production-ready APIs with built-in authentication, structured responses, and developer-friendly documentation optimized for AI consumption, eliminating the need to build security layers from scratch.
What does “exposing APIs to LLMs” mean?
Exposing APIs to large language models (LLMs) means allowing AI systems to call and interact with your enterprise systems through application programming interfaces. Instead of hard-coded requests from predictable clients like web apps or backend services, LLMs construct API calls dynamically based on natural language prompts or reasoning chains. The model gains the ability to read user profiles, process payments, or chain multiple calls using frameworks like OpenAI Functions or LangChain.
The Core Concept
When you expose an API to an LLM, you grant the model programmatic access to execute real-world operations, such as querying databases or fetching external data. Modern LLMs interpret user intent to determine which endpoints to call, extract parameters, and orchestrate multi-step workflows without hardcoded logic.
- Dynamic Orchestration: The LLM decides which tools to use based on conversation context rather than a fixed script.
- Action Execution: It translates natural language into structured requests to trigger business processes like shipping orders or updating records.
What It Doesn’t Mean
This does not mean removing authentication or making endpoints public. You must build a controlled interface where permissions, rate limits, and validation keep the model within safe boundaries. It requires enforcing strict scope limits to prevent the AI from accessing unauthorized data or exceeding its intended role.
Get Your Free API Keys!
Join thousands of developers using APILayer to power their applications with reliable APIs!
Get Your Free API Keys!100 Requests Free!
Why LLMs Break Traditional API Security Models
Large language models fundamentally shift the security landscape by acting as dynamic, probabilistic agents rather than predictable API consumers. Unlike traditional clients that follow hard-coded paths, LLMs reason at runtime, creating a broader and more erratic attack surface that static defenses often miss.
- The Unpredictability Problem: LLMs generate API requests based on probability and context, leading to varying outputs even for identical inputs. This dynamic behavior makes it nearly impossible to whitelist valid request patterns using traditional signature-based detection.
- Lack of Explicit Boundaries: Without strict schema enforcement, models can infer and attempt to access endpoints or parameters they shouldn’t know exist. They might try lateral access escalation or combine API calls in unforeseen ways that expose sensitive logic or data.
- Prompt Injection as an Attack Vector: Attackers can craft malicious inputs that trick the model into overriding its system instructions and executing unauthorized API calls. This semantic-layer attack bypasses network-level firewalls by using the model’s own reasoning capabilities to leak credentials or manipulate data.
- Scale and Automation Risks: AI agents operate at machine speed, meaning a single misconfiguration can trigger thousands of erroneous or malicious transactions in seconds. This automated amplification turns minor logic flaws into catastrophic, high-volume security incidents before human teams can react.
- The Illusion of Natural Language Safety: Conversational interfaces create a false sense of security by masking the complexity of underlying code execution. Developers may trust the “human-like” interaction, forgetting that the model is effectively executing arbitrary code on backend systems without traditional validation.
Understanding the LLM-API Attack Surface
When large language models connect to your APIs, they introduce a new attack surface where natural language becomes a potential vector for exploitation. Unlike traditional clients, LLMs can be manipulated to act as unsuspecting proxies, executing malicious logic that bypasses standard perimeter defenses.

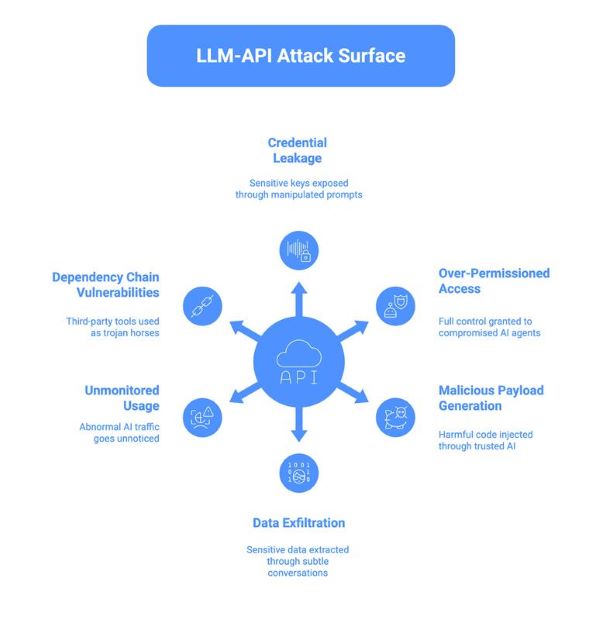
1. Credential leakage through prompt outputs
Developers often embed API keys or sensitive secrets directly into system prompts to simplify tool access, believing they are hidden from the user. However, attackers can use “jailbreak” techniques or specific queries to trick the model into repeating these instructions verbatim, exposing the credentials in the chat interface. Once revealed, these keys allow direct, unauthorized access to your backend systems, bypassing the LLM entirely.
2. Over-permissioned access tokens
Teams frequently assign a single, high-privilege API token to an AI agent to ensure it can handle any user request without errors. This violates the principle of least privilege, meaning if the agent is compromised via prompt injection, the attacker inherits full administrative control over all connected services. Secure implementations should instead use scoped, short-lived tokens that limit the agent’s reach to the specific task at hand.
3. Malicious payload generation
LLMs can be manipulated to generate and send harmful payloads, such as SQL injection strings or cross-site scripting (XSS) code, to your API endpoints. Since these payloads originate from a “trusted” internal AI service, they often bypass standard web application firewall (WAF) rules that only scrutinize external traffic. The model essentially acts as a proxy for the attacker, laundering malicious inputs into a format your API accepts as valid.
4. Data exfiltration via conversational patterns
Sophisticated attackers can engage in multi-turn conversations designed to slowly extract sensitive information that would be blocked in a single query. By asking indirect questions or spreading the request across multiple prompts, they can bypass simple keyword filters and aggregate data bits into a full breach. This method leverages the model’s context window to piece together protected records like transaction histories or PII without triggering volume-based alerts.
5. Unmonitored usage patterns
LLM-driven API traffic often looks different from human traffic, creating blind spots where abnormal behavior goes unnoticed. A compromised model might query thousands of user records in a short burst or access an unusual combination of endpoints that no human user would ever trigger. Without specific monitoring for these machine-speed patterns, security teams may fail to detect a breach until significant data loss has occurred.
6. Dependency chain vulnerabilities
Many AI agents rely on third-party plugins or external tools to function, each requiring its own set of API permissions. If one of these dependencies is compromised or malicious, it can act as a trojan horse, using the agent’s legitimate access to attack your internal network. These lateral attack vectors are difficult to track because the initial request appears to come from a valid, authorized component of your AI architecture.
To counter these risks, you must move beyond simple API keys and implement a robust identity framework that treats every LLM interaction as a distinct, verifiable session requiring strict authentication.
Identity and Access Management for LLMs
Securing LLMs requires moving beyond static keys to a robust identity framework that treats every model interaction as a distinct, verifiable session. This ensures that AI agents operate with the same strict governance as human users, minimizing the radius of any potential compromise.

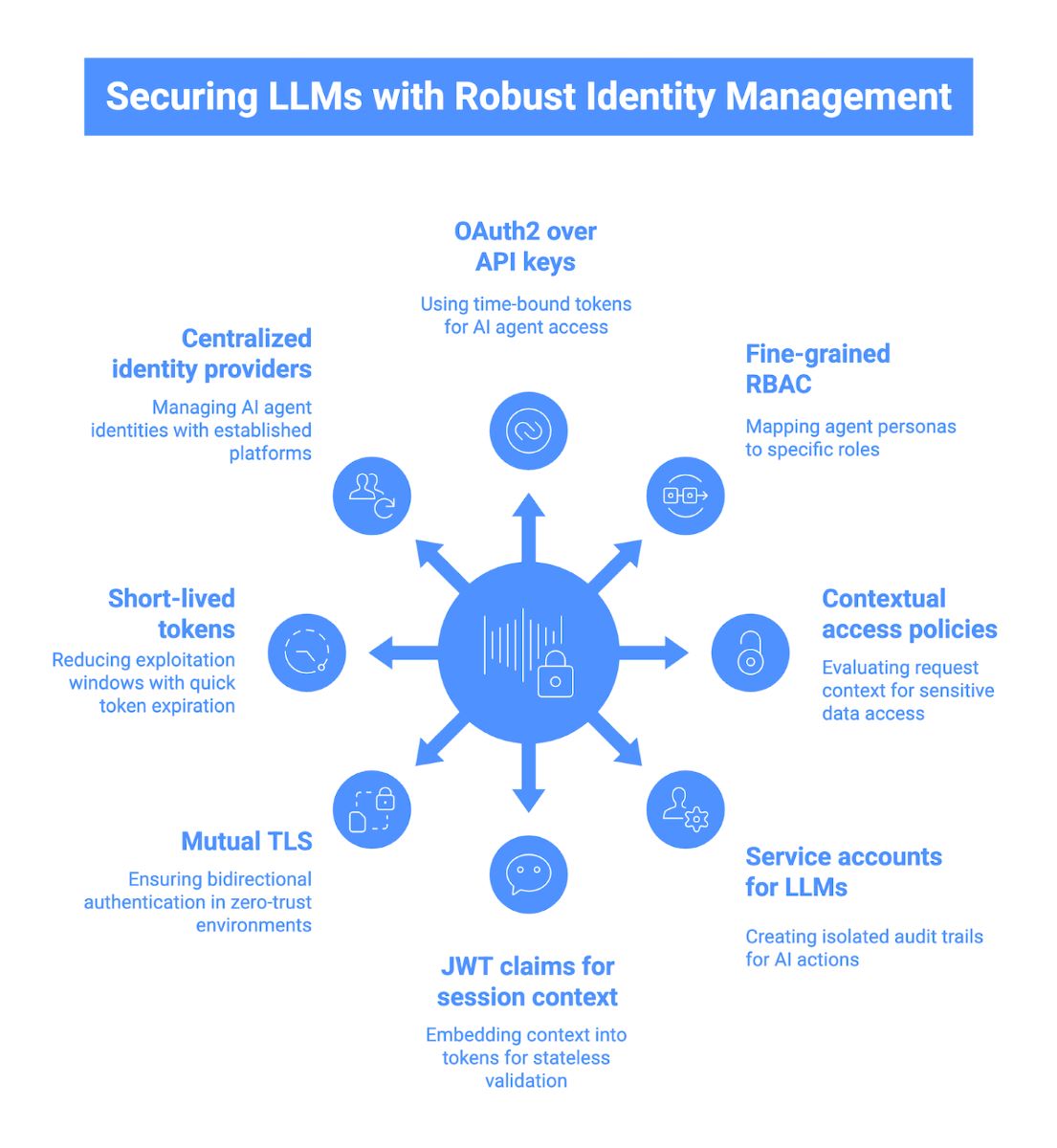
1. OAuth2 over API keys
Static API keys are dangerous for AI agents because they lack granularity and are hard to rotate without breaking services. Instead, use OAuth2 client credentials flow to issue time-bound access tokens with specific scopes, ensuring that even if a token is leaked via prompt injection, its lifespan is short and its privileges are limited.
2. Fine-grained role-based access control (RBAC)
Don’t give your LLM “admin” or “full access” permissions; instead, map specific agent personas to distinct roles with minimum necessary privileges. For example, a “Customer Support Bot” role should only have read access to order status endpoints, while explicitly denying write access to inventory or payment systems, preventing the model from hallucinating unauthorized actions.
3. Contextual access policies
Enforce dynamic policies that evaluate the context of each request at runtime, not just the identity of the caller. You can block an LLM from accessing sensitive PII if the request originates from an unusual IP address, occurs outside business hours, or if the prompt metadata indicates a low-confidence or high-risk user query.
4. Service accounts for LLMs
Create dedicated service identities for your AI agents rather than piggybacking on human user credentials or generic system logins. This provides a clear, isolated audit trail for every action the model performs, making it easier to trace anomalies back to a specific agent configuration rather than a shared generic account.
5. JWT claims for session context
Embed critical context such as the end-user’s tenant ID, subscription level, or specific permission scopes directly into the JSON Web Token (JWT) used by the LLM. This allows your API gateway to perform stateless validation of the agent’s authority to access specific data partitions without needing to query a central database for every single token usage.
6. Mutual TLS (mTLS) for high-security environments
In zero-trust architectures, implement mutual TLS to ensure bidirectional authentication where both the LLM application and the API server verify each other’s certificates. This prevents “man-in-the-middle” attacks and ensures that your API only accepts requests from authorized AI infrastructure, even if a valid bearer token is intercepted by an attacker.
7. Short-lived tokens with automatic rotation
Configure your identity provider to issue access tokens with very short lifespans (e.g., 15-60 minutes) for AI agents. This drastically reduces the window of opportunity for an attacker to exploit a stolen token, as it will expire quickly and require a re-authentication process that a malicious actor cannot easily replicate.
8. Centralized identity providers
Leverage established identity platforms like Okta, Auth0, or AWS IAM to manage the lifecycle of your LLM service accounts centrally. This ensures that security policies, such as password rotation and multi-factor authentication (where applicable), are applied consistently across all your AI agents, avoiding the pitfalls of ad-hoc, fragmented security implementations.
With identities and permissions locked down, the next step is to protect the secrets those identities rely on through secure storage and runtime injection so credentials never touch prompts, logs, or source code.
Secure Secret Management and Runtime Injection
Secure secret handling is non‑negotiable once LLMs can hit your APIs, because any leaked key can be replayed outside your guardrails at scale. Your goal is simple: keep credentials out of prompts, logs, and source code, and inject them safely at runtime from controlled systems.
- Never hardcode secrets: Hardcoding API keys in prompts, source files, or environment files checked into repos makes them trivial to harvest through model outputs or source control leaks. Treat any static key in code as a bug, and replace it with a reference to a managed secret that you can rotate and revoke centrally.
- Centralized secret stores: Use services like AWS Secrets Manager, Google Cloud Secret Manager, HashiCorp Vault, or Azure Key Vault to store credentials in encrypted form with access controlled by IAM policies. This lets you manage keys, passwords, and tokens in one place and apply consistent rotation, access control, and auditing rules.
- Runtime token injection: Fetch secrets just in time at runtime through sidecars, operators, or environment loaders instead of baking them into config files or prompts. The LLM wrapper or agent runtime should request a token for each call path, use it briefly, and then discard it from memory as soon as possible.
- Secrets rotation automation: Automate rotation so credentials update on a schedule or event without manual edits or service restarts. Many secret managers can rotate database passwords or API keys through built‑in workflows, which keeps exposure windows short and limits blast radius if a key leaks.
- Audit trails for secret access: Log every secret retrieval with who accessed it, which service used it, and when it happened. Send these logs to your SIEM so alerts fire on unusual access patterns, such as new services pulling high‑value secrets at odd times.
- Separation of concerns: Do not let LLM apps talk directly to secret stores; route them through a narrow internal service or proxy that handles secret fetches and token issuance. This keeps secret material away from prompts and model context and limits the impact of prompt injection or logging bugs inside the LLM stack.
- Temporary credentials for batch operations: For batch jobs or scheduled agents, mint short‑lived tokens that only work for that specific job or time window. Even if an LLM leaks such a token through output or logs, the credential expires quickly and cannot be reused for broad access.
Once secrets are secured and identities are verified, you need a centralized enforcement point where every LLM request passes through policy checks, rate limits, and monitoring before reaching your APIs.
API Gateway as the Enforcement Layer
An API Gateway serves as the centralized enforcement point for all incoming LLM requests, applying security policies before any traffic reaches your backend services. This choke point gives you a critical layer of control, preventing malformed or malicious API calls from ever touching your sensitive application logic.
- Centralized authentication and authorization: It validates every incoming token and its permissions at the edge, rejecting unauthorized LLM requests immediately.
- Rate limiting and throttling: The gateway protects your APIs from request floods by enforcing usage quotas and rejecting traffic spikes generated by misconfigured or malicious AI agents.
- Request and response filtering: It can inspect payloads to mask sensitive data, block known malicious inputs, and prevent confidential information from leaking out in model responses.
- Dynamic routing based on context: You can route LLM requests to different backend environments or models based on JWT claims, geolocation, or other metadata embedded in the request.
- Protocol translation: The gateway translates unstructured natural language intents into structured REST or GraphQL calls, ensuring every request conforms to a valid schema.
Securing the infrastructure is only half the battle; you must also engineer the prompts themselves to act as the final firewall against misuse.
Prompt Engineering for Secure API Access
Your system prompts and instruction act as the first line of defense, defining boundaries for what the LLM can and cannot do with your APIs. By embedding security constraints directly into the prompt structure, you reduce the risk of the model hallucinating unauthorized operations or falling victim to injection attacks.
- Strict instruction templates: Use fixed prompt formats that explicitly list allowed operations, required parameter formats, and forbidden actions so the model has clear guardrails for every API interaction.
- Whitelisting API endpoints: Explicitly enumerate the permitted endpoints in your system prompt with descriptions of their safe use cases, preventing the model from attempting to call undocumented or internal APIs.
- Parameter validation in prompts: Instruct the LLM to validate all input values for type, range, and format before constructing API requests, catching malformed or malicious payloads before they leave the prompt layer.
- Output sanitization directives: Embed explicit instructions for the model to strip sensitive fields like API keys, tokens, or PII from responses before displaying them to users, preventing accidental credential leakage.
- Multi-step reasoning with confirmation gates: Break high-risk workflows into stages where the LLM proposes an action, waits for human or policy approval, and only then executes the API call to prevent unauthorized transactions.
- Context window management: Limit how much API response data enters the model’s conversational memory to avoid information bleeding across sessions or being exposed through follow-up queries.
Finally, you must unify these individual controls identity, secrets management, gateways, and prompt engineering under a comprehensive Zero-Trust framework that treats every single LLM request as untrusted by default.
Implementing Zero-Trust Architecture for LLM-API Integration

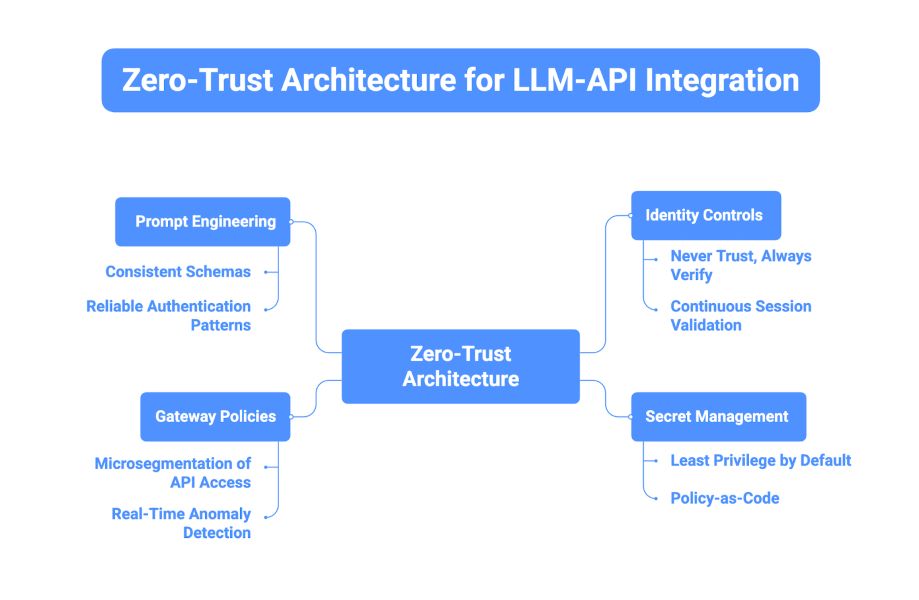
Zero-Trust architecture assumes that no request is inherently safe, requiring continuous verification at every stage of the LLM-to-API interaction. This framework unifies identity controls, secret management, gateway policies, and prompt engineering into a cohesive defense strategy where each layer reinforces the others.
- Never trust, always verify: Authenticate and authorize every single LLM-generated request in real time, regardless of whether it comes from a known service or has previously accessed the same endpoint successfully.
- Microsegmentation of API access: Use network-level isolation to ensure that your LLM services can only communicate with explicitly whitelisted API endpoints, blocking all lateral movement attempts at the infrastructure layer.
- Continuous session validation: Re-evaluate permissions and context on each API call instead of trusting long-lived sessions, so compromised tokens automatically lose access as soon as policies change.
- Least privilege by default: Start with zero permissions for your LLM agents and grant only the minimum access required for their specific tasks, expanding privileges only when a clear business justification exists.
- Real-time anomaly detection: Deploy behavioral analytics that flag unusual patterns such as unexpected geographic locations, abnormal request volumes, or endpoint combinations that no legitimate workflow would generate.
- Policy-as-code with version control: Define all access rules using declarative policy languages like OPA Rego or Cedar, storing them in Git so you can track changes, roll back bad policies, and audit who approved what permissions.
Implementing these zero-trust controls is easier when you build on APIs that already provide consistent schemas, reliable authentication patterns, and predictable behavior rather than integrating with unverified or poorly documented endpoints.
APILayer: Verified APIs for Secure LLM Integration
Building AI agents from scratch is slow, and feeding them the right data is even harder. APILayer solves this “cold start” problem with a marketplace of MCP-ready APIs for AI integration that instantly give your LLMs real-world capabilities, from financial intelligence to geolocation awareness, without the maintenance headache of custom scrapers or unverified data sources.
The Core Stack for AI Agents
Give your AI agents with essential tools that map directly to common LLM use cases:
- Geolocation & Context (IPstack): Give your agent spatial awareness to build an AI agent for fraud detection or personalize content based on user location.
- Financial Intelligence (Marketstack, Fixer): Provide real-time stock data and currency exchange rates with strict JSON schemas that prevent LLM hallucination.
- Verification (Numverify): Validate phone numbers and other user inputs before your agent triggers database writes, adding a defense layer against injection attacks.
- Visual Capture (Screenshotlayer): Enable your agents to “see” the web by capturing high-resolution screenshots of URLs to monitor competitors, verify ad placements, or generate visual summaries of web content automatically.
Why It Matters for Security & Speed
- Unified Authentication: Manage one consistent API key structure across all tools, simplifying secret rotation and environment security.
- Predictable Integration: Standardized JSON responses and HTTP error codes mean you write one error-handling wrapper for your entire agent stack.
- Enterprise Compliance: Inherit HTTPS encryption and GDPR compliance by default, ensuring your AI data pipelines are secure from day one.
Conclusion
Exposing APIs to LLMs safely is not about choosing between innovation and security; it’s about building systems where both work together. The unpredictable nature of large language models demands architectural patterns that traditional API security never anticipated, including dynamic scope enforcement, runtime guardrails, and behavioral monitoring that adapts to AI-generated requests.
By implementing layered defenses like OAuth2 with fine-grained RBAC, API gateways as enforcement checkpoints, zero-trust network segmentation, and comprehensive observability, you create an environment where LLMs can access production data without compromising your security posture. Structured prompt engineering adds another dimension, constraining model behavior before requests even reach your infrastructure.
APILayer provides production-ready APIs that offer a secure foundation for AI integration. With built-in authentication, predictable JSON schemas, and developer-friendly documentation, you can connect LLMs to real-world data like geolocation, financial markets, currency conversion, and email validation without building security layers from scratch. The result is faster development cycles and fewer vulnerabilities, letting you focus on building intelligent applications instead of debugging API security gaps.
FAQs
1. Should I use API keys or OAuth2 for my LLM agents?
Skip API keys and go straight to OAuth2 with client credentials flow. API keys are static and can’t be scoped down, so if your LLM leaks one through a prompt injection, the attacker gets full access to everything that key controls.
2. How do I stop my LLM from leaking API credentials in chat responses?
Never put secrets in system prompts or let the LLM handle credentials directly. Instead, store keys in a secrets manager like AWS Secrets Manager and inject them at runtime through a backend service that sits between your LLM and your APIs.
3. What’s the fastest way to detect if my AI agent is under attack?
Set up behavioral monitoring that flags unusual patterns like sudden spikes in API calls, requests from weird IP addresses, or endpoint combinations that no legitimate workflow would generate. Most breaches happen at machine speed, so automated alerts catch problems before they spiral into major incidents.
4. Do I really need an API gateway just for LLM traffic?
Yes, because the gateway becomes your single enforcement point for authentication, rate limiting, and request filtering before any LLM-generated traffic touches your backend. Without it, you’re relying on the LLM itself to follow rules, which is exactly what prompt injection attacks exploit.
5. How do I validate user input before it reaches my LLM?
Run all external inputs through sanitization filters that strip special characters, validate formats, and check against known malicious patterns before feeding them to your model. You can also use dedicated validation APIs to verify phone numbers, emails, or geo data at the input layer, catching bad data before it becomes a prompt injection vector.
6. Can I trust my LLM to handle its own permissions?
No, authentication and authorization must happen outside the LLM context, not through prompt instructions. A skilled attacker can use prompt injection to trick the model into ignoring its own rules or impersonating other users, so your API layer needs to enforce permissions independently.
7. How does APILayer help secure my AI agent integrations?
APILayer provides pre-built APIs like IPstack, Numverify, and Marketstack with consistent authentication patterns and structured JSON responses that prevent LLM hallucination. You get one unified key management system across all tools, plus built-in HTTPS encryption and GDPR compliance, so you skip the security setup phase and start building agents faster.
Recommended Resource :
- Build an AI Agent for Fraud Detection Using Python, LangChain, and ipstack
- Top 10 MCP-Ready APIs for AI Integration in 2025 — Making Your API Data Accessible to ChatGPT and Claude 2
- Build Location-Aware AI Chatbots with ipstack