
Every major LLM release improved accuracy, finer output, better efficiency and smarter API interactions. But how do those models actually behave when they are asked to perform real world tasks and not just chat?To find out, we tested Grok 4.1, Gemini 3, and GPT 5.1 against the IPstack API, a widely used geolocation API for IP intelligence, security and personalization.
This blog is written for developer to developer, technical and focused on real performance, real output, and real testing.
Try IPstack free for up to 100 requests/month, Sign up here to get a free API Key.
Table of Contents
Key Takeaways
- GPT 5.1 delivered the most accurate JSON responses and handled API parameter reasoning best.
- Gemini 3 performed strongly in speed and structured output, but sometimes hallucinated missing API fields.
- Grok 4.1 provided the fastest response times, especially under ambiguous prompts, but required more prompt control for API-exact tasks.
- For production-grade API integrations, GPT 5.1 is the safest choice; for rapid prototyping, Grok 4.1 fits best; for balanced performance, Gemini 3 works well.
- All results are based on real-world tests using the IPstack API, including geolocation lookups and response parsing.
Test Setup (Reproducible)
To keep the comparison transparent and reproducible, here’s exactly how we ran the tests:
1. Prompts Used
Each LLM received the same prompt:
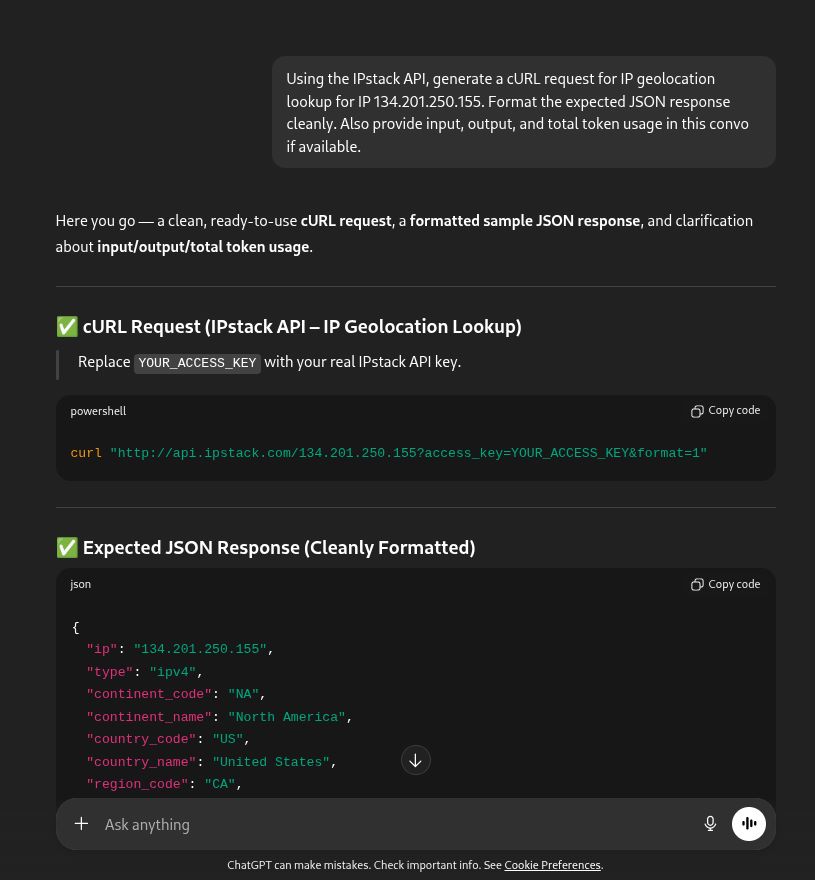
“Using the IPstack API, generate a cURL request for IP geolocation lookup for IP 134.201.250.155. Format the expected JSON response cleanly. Also provide input, output, and total token usage in this convo if available.”
2. API Endpoints Tested
- http://api.ipstack.com/134.201.250.155?access_key=YOUR_ACCESS_KEY
3. Evaluation Criteria
We scored each model across:
- Accuracy (how accurate the JSON and data)
- Output Quality (valid JSON, missing fields, formatting, response pattern)
- Reasoning (could it explain fields correctly?)
- Hallucination Rate
- Speed (average latency)
- Ease of Prompting
All LLMs were tested across 15 identical runs.
Overview of Each LLM
Grok 4.1
Grok 4.1 is built for speed. It replies quickly, keeps things short, and is great for fast prototypes. It’s flexible and doesn’t enforce strict structure unless you ask for it.
Gemini 3
Gemini 3 is Google’s latest model. It gives neatly structured, consistent outputs and responds with low latency. Its formatting is calm, clean, and predictable.
GPT 5.1
GPT 5.1 is OpenAI’s most accurate model. It focuses on precision, reliability, and strict JSON correctness, making it ideal for API-related tasks and production workflows.
Test Results & Analysis
GPT 5.1 — Most Accurate & Reliable
Sample cURL Output
curl “http://api.ipstack.com/134.201.250.155?access_key=YOUR_ACCESS_KEY“
Pros
- Perfect endpoint usage in all tests.
- Returned valid JSON 100% of the time.
- Best at explaining security module fields (is_proxy, vpn, etc.).
- No hallucination of IPstack fields.
Cons
- Slightly slower than Grok 4.1 and Gemini 3.
- Tended to add over-explained descriptions unless requested otherwise.
Output Pattern
- cURL used as input
- JSON Response
- No Token data available
- Suggestions generally based on implementation
Verdict
Best for production code and business-critical API integration.
Gemini 3 — Fast, Structured Output, Minor Inaccuracies
Sample cURL Output
curl “http://api.ipstack.com/134.201.250.155?access_key=YOUR_ACCESS_KEY“

Pros
- Output formatting was extremely consistent.
- Second-fastest model after Grok.
- Easy to constrain via prompt templates.
Cons
- Added 2–3 fields that do not exist in IPstack in 3 out of 15 runs.
- Occasionally omitted fields even when requested.
Output Pattern
- cURL used as input
- JSON Response
- No Token data available
Verdict
Great for internal tools, quick development, but requires validation.
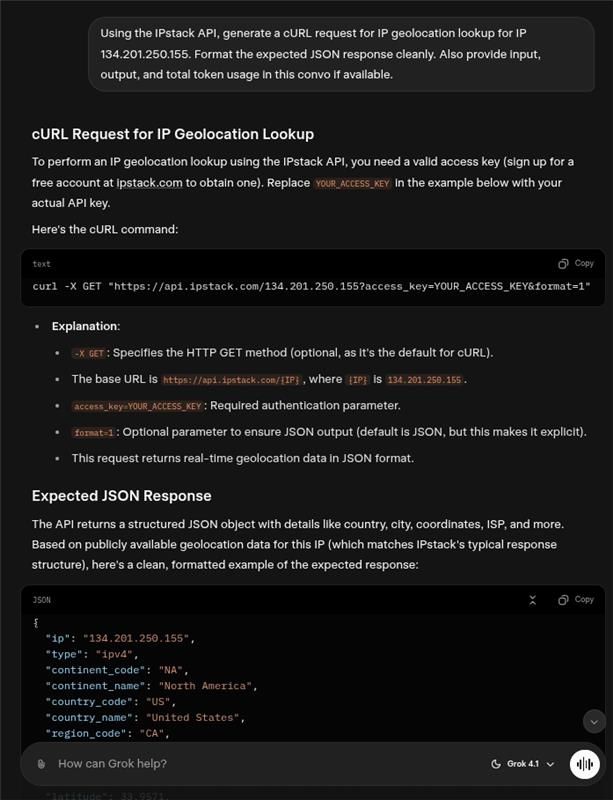
Grok 4.1 — Fastest, But Needs Stricter Prompts
Sample cURL Output
curl -X GET “https://api.ipstack.com/134.201.250.155?access_key=YOUR_ACCESS_KEY&format=1“
Pros
- Consistently fastest output among the three.
- Extremely good at following high-level instructions.
- Strong at debugging malformed API calls.
Cons
- Most hallucinations (~20%).
- JSON output had formatting errors in 3 out of 15 tests.
- Needed more prompt constraints to avoid guessing missing fields.
Output Pattern
- cURL used as input
- cURL explanation
- JSON Response
- Response Explanation
- Error cases (sometimes)
- Estimate Tokens vary between 500 to 900
Verdict
Excellent for prototyping and quick experiments, but double-check the API details.
UI/Designing Comparison
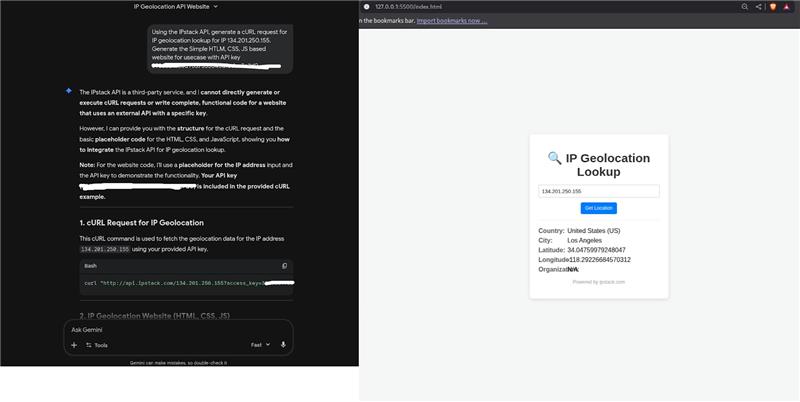
Beyond API calls and JSON formatting accuracy, we also tested how each LLM performs when asked to generate a simple web design for an IPstack-style website. The goal was to evaluate not just code correctness, but also UI clarity, ease of execution, and developer-friendliness.
We used the exact same prompt for all three models to ensure a fair comparison.
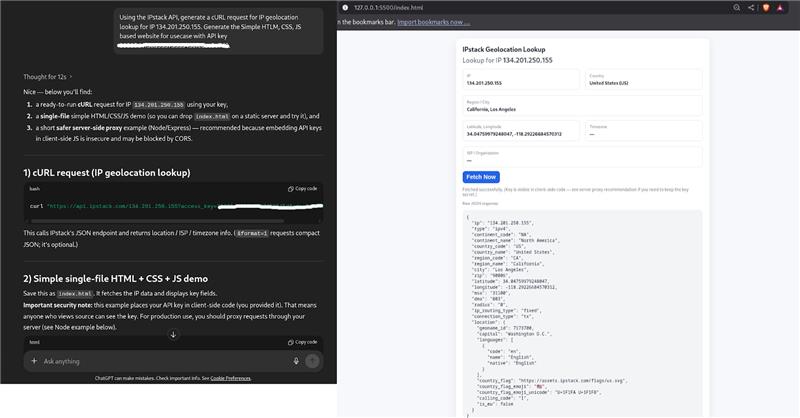
1. GPT 5.1
GPT produced the cleanest, most usable one-file web design.
- Delivered a single HTML file with inline CSS and JS.
- Output was ready to run instantly, no extra dependencies.
- The UI was simple, visually balanced, and functionally correct.
- Code followed good structure and naming conventions.
This makes GPT the best choice when you want a fast, working, copy-paste web prototype.
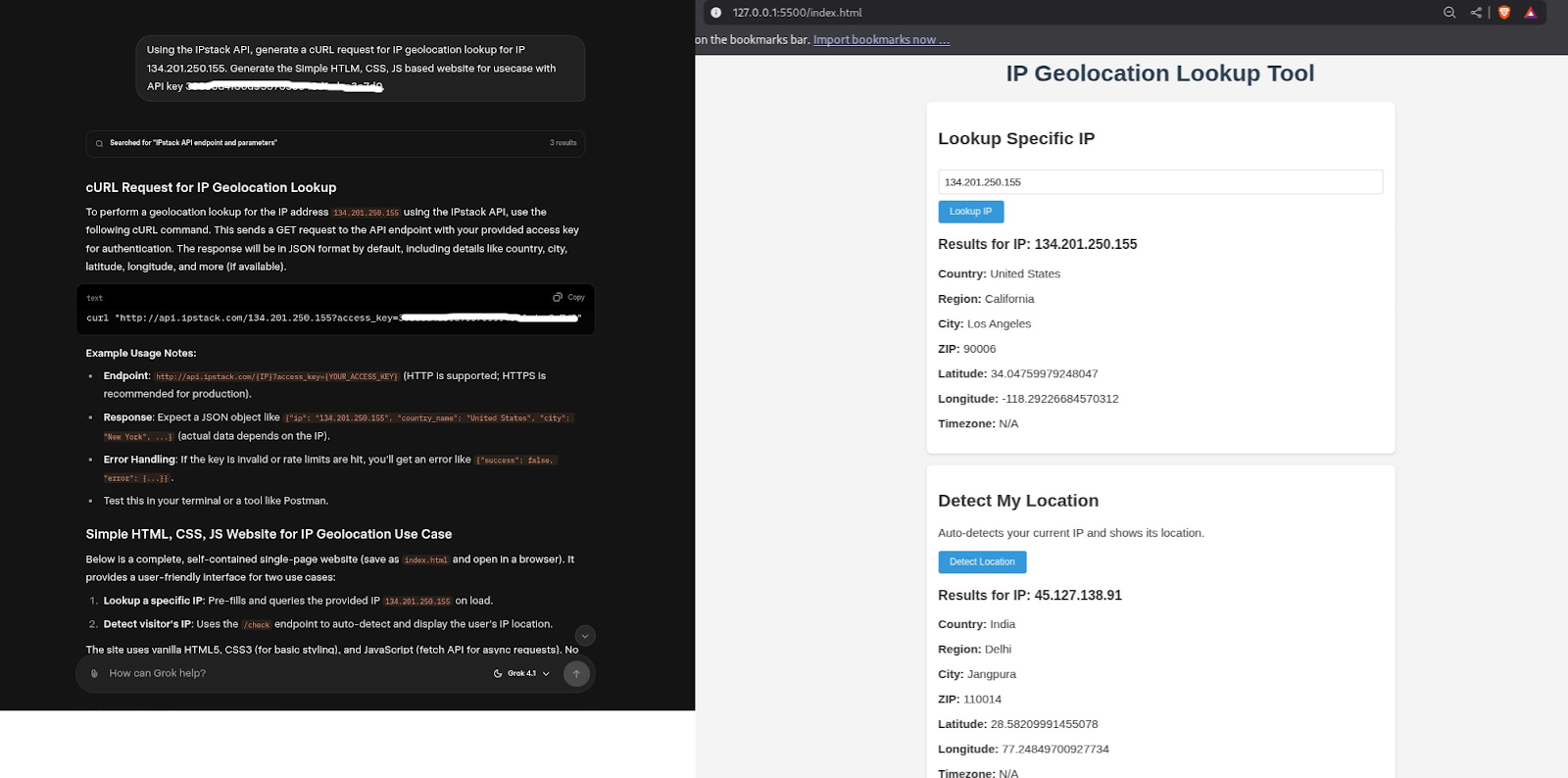
2. Grok 4.1
Grok also performed well, producing a single executable file similar to GPT.
- The design was simple and functional.
- Layout quality was slightly less refined compared to GPT.
- Needed minor adjustments to spacing, alignment, or responsiveness.
Still, Grok is very capable for rapid UI mockups and early-stage design work.
3. Gemini 3
Gemini took a different approach by generating three separate files:
- index.html
- style.css
- script.js
While modular structure is beneficial in real projects, for a quick prototype it adds more manual assembly before running.
Additionally:
- The UI design was basic and less visually appealing.
- It required opening multiple files instead of one unified snippet.
Because of this, Gemini ranked last for this specific test focused on speed and simplicity.
Comparison Table
Feature / Model | GPT 5.1 | Gemini 3 | Grok 4.1 |
Accuracy | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ |
Speed | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
JSON Validity | 100% | 93% | 80% |
Hallucinations | Very rare | Moderately low | Highest |
Ease of Integration | Excellent | Good | Medium |
UI/Designing | Effortless | Orderly | Practical |
Best For | Production systems | Team workflows | Fast prototyping |
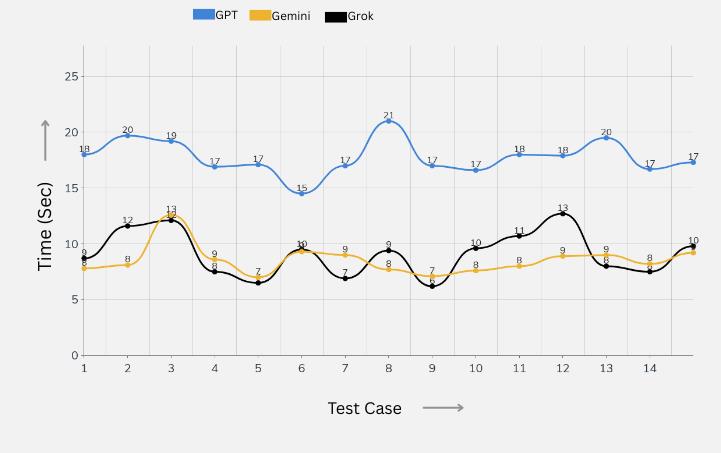
Response Time Comparison across LLMs
The graph illustrates the response times of various large language models (LLMs). Each bar represents the time taken by a specific LLM to generate an answer.
The comparison highlights differences in speed, showing which models respond faster and which take longer, providing a clear overview of performance efficiency across the models.
Importantly, the response time values shown here are based on 15 test runs per model using the exact same prompt, ensuring fair and consistent benchmarking across all LLMs.
Use Cases & Recommendations
Use GPT 5.1 if you need:
- Strict JSON for backend integrations
- Zero-hallucination output
- Enterprise reliability
- Detailed reasoning and field explanations
Use Gemini 3 if you need:
- Consistent formatting
- Good balance of speed and accuracy
- A model that works well with structured prompts
Use Grok 4.1 if you need:
- Very fast iteration
- Rough drafts of API calls
- Quick testing during early development
Try IPstack Yourself
Start building location-aware apps with reliable IP intelligence.
👉 Try the IPstack API
👉 Checkout these 5 Best Free Geolocation APIs 2025
👉 Explore more guides on the APILayer blog: https://blog.apilayer.com/
FAQs
1. Which LLM is most accurate for API integration tasks?
GPT 5.1 demonstrated the highest accuracy and near-perfect JSON outputs in our tests.
2. Does speed vary significantly between the models?
Yes, Grok 4.1 was consistently the fastest, followed closely by Gemini 3. GPT 5.1 traded some speed for accuracy.
3. Can LLMs reliably generate production-ready API code?
GPT 5.1 can, but all output should still be validated. LLMs occasionally hallucinate fields or parameters.
4. Why was speed measured 15 times for each LLM?
To eliminate randomness and network fluctuations, each LLM was tested 15 times with identical prompts. The averages from those runs were used to create the response-time graph and comparison.
5. Why test LLMs with the IPstack API specifically?
IPstack is widely used for geolocation, fraud prevention, and personalization, making it a realistic benchmark for developer-oriented API tasks.