
Traditional Retrieval-Augmented Generation (RAG) systems are a lot like those well-organized libraries we all know. They keep information tucked away in pre-indexed databases, pulling out the right documents whenever someone asks a question. This setup handles stable, unchanging facts just fine, but it runs into real trouble with stuff that’s always shifting and evolving.
The classic RAG setup depends on fixed knowledge bases that can go stale pretty fast. These systems hit what experts call “knowledge boundaries” , those spots where large language models (LLMs) don’t have the latest facts, which often leads them to just make things up. At the heart of it, the problem is how these models handle info: they focus more on spitting out smooth, logical-sounding answers than on getting the facts straight, especially when the data’s spotty or old.
Table of Contents
You will learn:
- Uncover why traditional RAG falls short and how Smart RAG uses real-time APIs to deliver accurate, fresh responses.
- Use APILayer APIs like Marketstack for stocks and Weatherstack for weather, with easy code for instant setup.
- Build a complete Smart RAG architecture, including query handling, data pipelines, AI agents, and scalable MCP servers.
- Create real-time data pipelines with Python code to fetch, embed, and store info in Pinecone for dynamic AI.
- Integrate APIs into RAG for smarter LLM prompts, plus real-world cases like financial agents and travel assistants.
- Scale with multi-agent systems, optimize speed, secure errors, and measure success through latency and accuracy.
When you ask LLMs about fast-changing topics like stock markets or today’s weather, they often end up hallucinating, basically inventing details. They do this because they are using patterns from their training data instead of facts from the present. For example, a financial advice chatbot built on old-school RAG might give users stock quotes from a few weeks ago, which could lead them to make some really bad funds decisions.
That’s why we’re seeing the rise of “Smart” RAG systems that tap into live, outside data sources. Rather than sticking to what’s already stored, these upgraded versions reach out via APIs for the most current info, making sure their answers capture what’s happening right now instead of some outdated version of events.
This article discusses a “smart” RAG system which uses real-time data from APILayer’s Marketstack and Weatherstack APIs to provide LLM-powered AI agents and assistants current context.
Overview of APILayer’s Marketstack and Weatherstack APIs
Let’s talk about two great APIs from APILayer that can really boost your projects. These are based on what we talked about before about how to make RAG systems smarter with real-time data. I’ll keep things simple so you can understand. Have you ever thought about how to quickly get updates on the weather or stock prices? These APIs make it easy. We’ll talk about each one, highlighting its main features, showing you how to use it, and giving you tips on how to get started. You can copy and paste the code snippets and try them out yourself.
Marketstack API: The Best Place for Stock Data
Marketstack has a lot of financial market data from 72 exchanges around the world and more than 125,000 stock tickers. The API delivers real-time, intraday, and historical data spanning 30 years, giving developers access to the same information used by major companies like Microsoft, Amazon, and Credit Suisse. This enables financial applications to provide up-to-the-minute market insights rather than stale information.

What makes it handy? You get features like ticker lookups, exchange details, and bulk queries, all in easy-to-handle JSON format. This means low wait times and smooth fits into your AI setups.
Want to see it in action? Check this endpoint example for end-of-day data on Apple’s stocks. Just swap in your access key.
Example API Request:
https://api.marketstack.com/v2/eod
? access_key = YOUR_ACCESS_KEY
& symbols = AAPL
Example API Response:
{
"pagination": {
"limit": 100,
"offset": 0,
"count": 100,
"total": 9944
},
"data": [
{
"open": 228.46,
"high": 229.52,
"low": 227.3,
"close": 227.79,
"volume": 34025967.0,
"adj_high": 229.52,
"adj_low": 227.3,
"adj_close": 227.79,
"adj_open": 228.46,
"adj_volume": 34025967.0,
"split_factor": 1.0,
"dividend": 0.0,
"name": "Apple Inc",
"exchange_code": "NASDAQ",
"asset_type": "Stock",
"price_currency": "usd",
"symbol": "AAPL",
"exchange": "XNAS",
"date": "2024-09-27T00:00:00+0000"
},
[...]
]
}
Running that would give you something like open price, high, low, close, and volume for the day. Pretty cool, right? If you’re on the free plan, you can make up to 100 calls per month, which is great for testing ideas.
Weatherstack API: Fresh Weather Info at Your Fingertips
Weatherstack offers weather information from around the world through a flexible REST API that can scale. More than 75,000 businesses around the world depend on it for up-to-the-minute weather information, historical records going back 11 years, and forecasts for up to two weeks in the future for many places. It works with many languages and has useful features like spot searches, astronomy insights, and batch requests. This makes it great for apps that help you plan trips, shipping companies, and any service that has to do with locations.

Key benefits? Location-based searches, support for multiple languages, and bulk options make it flexible. Plus, you can grab 11 years of past data or 14-day forecasts.
Here’s a simple endpoint to get current conditions in New York. Plug in your key and give it a go.
Example API Request:
https://api.weatherstack.com/current
? access_key = YOUR_ACCESS_KEY
& query = New York
Example API Response:
{
"request": {
"type": "City",
"query": "New York, United States of America",
"language": "en",
"unit": "m"
},
"location": {
"name": "New York",
"country": "United States of America",
"region": "New York",
"lat": "40.714",
"lon": "-74.006",
"timezone_id": "America/New_York",
"localtime": "2019-09-07 08:14",
"localtime_epoch": 1567844040,
"utc_offset": "-4.0"
},
"current": {
"observation_time": "12:14 PM",
"temperature": 13,
"weather_code": 113,
"weather_icons": [
"https://assets.weatherstack.com/images/wsymbols01_png_64/wsymbol_0001_sunny.png"
],
"weather_descriptions": [
"Sunny"
],
"astro": {
"sunrise": "06:31 AM",
"sunset": "05:47 PM",
"moonrise": "06:56 AM",
"moonset": "06:47 PM",
"moon_phase": "Waxing Crescent",
"moon_illumination": 0
},
"air_quality": {
"co": "468.05",
"no2": "32.005",
"o3": "55",
"so2": "7.4",
"pm2_5": "6.66",
"pm10": "6.66",
"us-epa-index": "1",
"gb-defra-index": "1"
},
"wind_speed": 0,
"wind_degree": 349,
"wind_dir": "N",
"pressure": 1010,
"precip": 0,
"humidity": 90,
"cloudcover": 0,
"feelslike": 13,
"uv_index": 4,
"visibility": 16
}
}
That call returns JSON with current temp, weather description, and more. On the free tier, you get a solid number of calls each month to start experimenting, just think thousands depending on your plan. It’s perfect for adding that live edge to your RAG systems.
These APIs transform traditional RAG systems from static information retrievers into dynamic, context-aware assistants that can provide accurate, timely responses to user queries about rapidly changing conditions.
Now, lets see how these API can fit into smart RAG system
System Architecture for a Smart RAG System
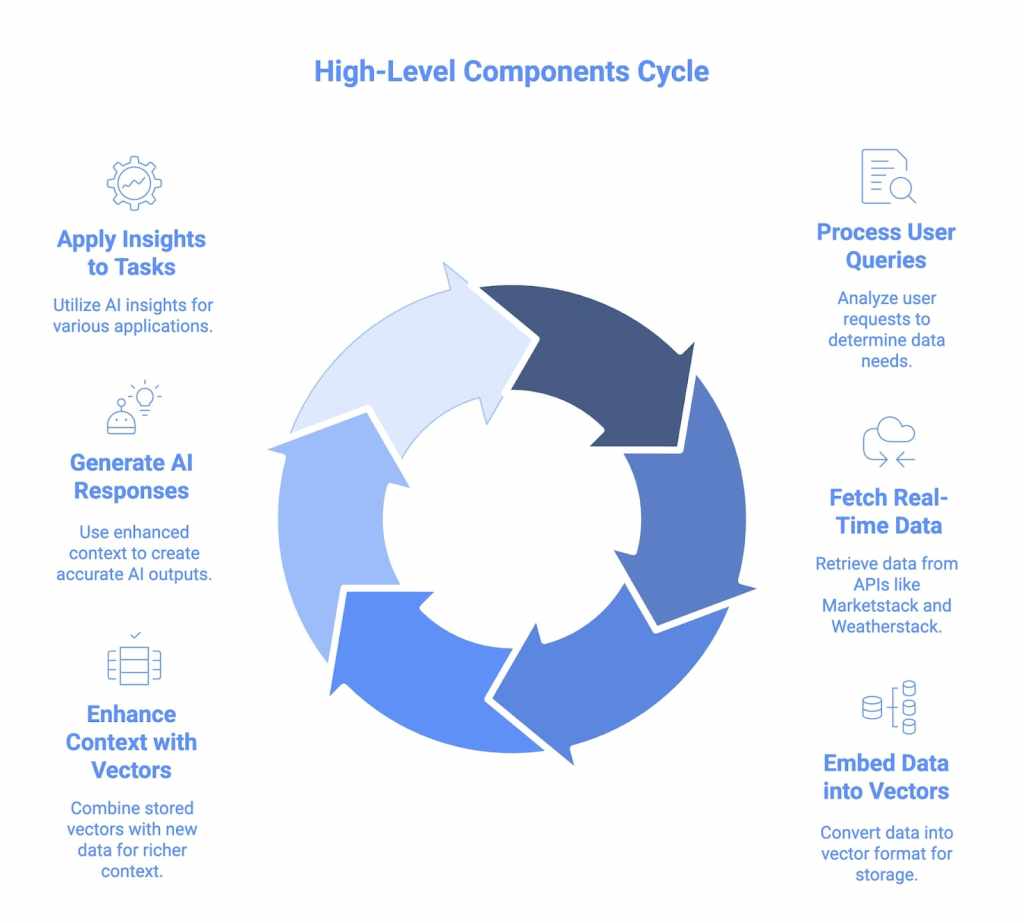
We design this Smart RAG system with modules that work together smoothly to fetch real-time data, embed it, retrieve what we need, and generate responses. It starts by pulling fresh info through APIs, turns that data into vectors stored in databases like Pinecone for quick access, and then uses LLMs such as GPT or Llama to reason and create accurate outputs. This setup keeps everything current and efficient, letting AI apps handle dynamic queries without missing a beat.
High-Level Components
Let’s break down the main parts of this architecture. I’ve added some extra details to each one, including how APILayer APIs like Marketstack and Weatherstack fit in to boost real-time capabilities.
Query Processor
This part starts by looking at what users want to find, like weather updates or financial information. It figures out if the query needs real-time data from places like Marketstack for stock prices or Weatherstack for forecasts, and it only sends the right parts to the system. This speeds up the rest of the process and makes it more useful for AI assistants.
Data Pipelines
Here, data pipelines orchestrate API calls to fetch live responses, process them, and embed the info into vectors for storage. They integrate with APILayer APIs to pull real-time data, like market trends from Marketstack or current conditions from Weatherstack, then feed it into vector databases like Pinecone. This keeps everything flowing in real time, making sure AI apps stay up to date with fresh insights.
RAG Core
The RAG core gets extra context from the vector storage and sends it to the LLM to be made. It combines stored vectors with new data from the real world to make rich inputs, which helps the system avoid using old information in its responses. This central piece links retrieval and generation, making sure that outputs are reliable for a lot of different AI tasks.
AI Agents and Assistants
AI agents and assistants are like different parts that can work together to solve problems. For instance, they can use Weatherstack to see how the weather affects the market and Marketstack to see how the market affects the weather. LLMs help AI apps break down tough questions, work together on steps, and give smart answers. With this setup, they can deal with tough problems, like making travel plans based on changes in the market and weather forecasts.
Now, we are clear with high-level components, let’s start with setting up environment and building data pipelines.
Setting Up the Development Environment
Prepare a Python-based setup for building the smart RAG system.
Prerequisites:
- Python 3.10+.
- Libraries: langchain, pinecone-client, requests, openai (for LLM), pydantic for structured outputs.
- API Keys: Obtain from APILayer dashboard.
- Vector DB: Initialize Pinecone index with dimensionality matching your embeddings (e.g., 1536 for OpenAI)
Installation Code:
pip install langchain pinecone-client requests openai pydantic
Building Data Pipelines for Real-Time API Integration
We put together these pipelines to snag and manage data right as it comes in from user questions, which really amps up RAG retrieval by tossing in fresh context that those fixed sources just can’t touch. They operate by picking out the important bits from queries, hitting up APIs like Marketstack or Weatherstack for the latest scoop, and then weaving that into vector databases so it’s ready to grab during the response-building phase. This approach makes sure answers stay spot-on and up-to-date, particularly for tools handling quick-shifting details like market trends or weather patterns.
Pipeline Design:
- Trigger: An LLM digs into the user’s question to spot key elements, like ticker symbols or place names, which gets the whole pipeline rolling.
- Fetch: Depending on what the query’s about, the system fires off targeted API requests, drawing in info from spots like Marketstack for money matters or Weatherstack for weather reports.
- Process: It breaks down the JSON that comes back, turns the data into embeddings, and slides them into a vector setup like Pinecone to keep everything stored and accessible.
- Real-Time Handling: When it’s live in production, things like webhooks or regular checks ensure the data stays current by pulling in updates on their own.
Working Code: Dynamic API Fetch Function
Here’s a handy Python function that pulls data from APIs and tucks it into Pinecone. Give it a whirl by loading your env vars and plugging in some test details, swap in an actual stock ticker or city name to watch it in action!
import os
import requests
from langchain.embeddings.openai import OpenAIEmbeddings
from pinecone import Pinecone
embeddings = OpenAIEmbeddings()
pc = Pinecone(api_key=os.getenv('PINECONE_API_KEY'))
index = pc.Index('rag-index')
def fetch_and_embed(query_type, params):
if query_type == 'financial':
url = f"http://api.marketstack.com/v2/eod?access_key={os.getenv('MARKETSTACK_KEY')}&symbols={params['symbol']}"
elif query_type == 'weather':
url = f"http://api.weatherstack.com/current?access_key={os.getenv('WEATHERSTACK_KEY')}&query={params['location']}"
else:
raise ValueError("Invalid query type")
response = requests.get(url)
data = response.json()
# Embed and upsert to Pinecone
vector = embeddings.embed_query(str(data))
index.upsert([('id-1', vector, {'data': data})])
return data
This function checks the query type to build the right API URL, grabs the JSON data with a GET request, and then embeds it as a vector before upserting to Pinecone for RAG use.
It returns the raw data for further steps, making it easy to integrate into larger pipelines while handling errors like invalid types right away
Integrating APIs with RAG for LLM Augmentation
Now, we make the RAG process better by pulling in real-time data from APIs and putting it right into the LLM prompts. This allows the models to base their answers on new information instead of old training data. It keeps things right for queries that change quickly, like checking the weather or stock prices, which makes the whole system much more useful and reliable. In the end, it makes basic RAG a better choice for apps that need information right away.
RAG Workflow
Retrieve from vector DB using similarity search: The system digs into the vector database, say Pinecone, to hunt down the closest matching stored bits that line up with what the user asked.
Add fetched data to the prompt: It adds the new data from those API calls to the prompt, giving the LLM more information to work with.
Generate response via LLM: The LLM takes that pumped-up prompt and makes a strong, well-informed response.
Working Code: Full RAG Query Handler
Take a look at this Python code that manages queries by pulling data, embedding it, and cranking out responses. You can fire it up on your end once you’ve got your keys and libraries sorted, play around with various questions to catch the full effect!
from langchain.llms import OpenAI
from langchain.chains import RetrievalQA
from langchain.vectorstores import Pinecone as PineconeStore
llm = OpenAI(temperature=0.7)
vectorstore = PineconeStore(index, embeddings.embed_query, 'text')
def handle_query(user_query):
# Parse query to determine type (simplified)
if 'stock' in user_query.lower():
data = fetch_and_embed('financial', {'symbol': 'AAPL'})
elif 'weather' in user_query.lower():
data = fetch_and_embed('weather', {'location': 'New York'})
qa = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=vectorstore.as_retriever())
response = qa.run(user_query + f" Context: {data}")
return response
Example usage: handle_query(“Analyze AAPL stock with current New York weather for travel planning.”)
The function kicks off by scanning the query for terms like ‘stock’ or ‘weather’ to grab and embed the right data via that fetch_and_embed function from before, which keeps everything nicely dynamic.
It then sets up a RetrievalQA chain with the LLM, adds the fetched data to the query context, and runs it to generate a response you can use right away.
Use Case: Financial Analysis AI Agent
- An AI agent chains API calls to get stock trends from Marketstack and links them with weather impacts from Weatherstack, helping with tasks like logistics planning.
- For example, it might analyze how bad weather affects shipping stocks, giving users clear insights for better decisions.
Use Case: Travel Planning AI Assistant
- AI assistants pull forecasts from Weatherstack and currency rates from Marketstack to craft trip suggestions that fit current conditions and costs.
- This setup lets them offer tips like avoiding rainy spots or finding cheap flights based on exchange rates, making plans more personal and practical.
Scaling with AI Agents and Optimization
Alright, we’ve gone through a bunch on Smart RAG systems, starting from the fundamentals all the way to those code snippets, and now it’s time to level things up with some deeper thoughts on scaling and tweaking for better performance.
AI Agents in RAG
- You set up multi-agent setups by handing out particular jobs to various agents for example, one could handle the API pulls to grab info from places like Marketstack or Weatherstack, while another takes care of the LLM side for putting together the actual responses.
- Then, roll out these agents onto MCP servers to get that distributed computing going, which divvies up the tasks across a bunch of machines and ensures everything hums along nicely, even when the traffic spikes.
Optimization Techniques
- Sharpen your retrievers by tuning them with data that’s tailored to the field, such as digging into financial docs for stock-related questions or weather trends for predictions, which bumps up how precise and quick the searches turn out.
- Keep an eye on those API rate caps to dodge any bottlenecks, and throw in caching for the queries that pop up often, tucking away the results for a bit so the system can fire back answers quicker without hitting the same calls over and over.
Error Handling and Safety
- Set up try-except blocks around your API requests to catch any problems without crashing everything. Also, be ready with backups, like using stored data or letting users know about the problem.
- Clean up everything that comes in so that junk doesn’t cause problems, and keep your keys safe in environment variables or other secure places to avoid any mistakes.
Metrics for Performance
- Keep track of latency by timing each step, from breaking down the query to coming up with the answer, and use tools to write down these numbers so you can look at them later.
- Check how accurate things are and how happy users seem by doing ongoing tests, like throwing in example questions and getting feedback to make the setup better as you go.

Conclusion
We’ve covered a lot, from the limits of old RAG systems to how we can make them smarter with real-time data from external APIs. This whole process relies on strong data pipelines and well-planned API calls to keep information fresh and accurate. You can make AI apps and assistants that are truly “smart” and aware of their surroundings by using this method. You’re going beyond static responses and making interactions that are more dynamic, smart, and human-like.
Try out APILayer’s APIs and start making your own real-time AI solutions right away.
FAQs
What limits traditional RAG systems?
Traditional RAG systems rely on static knowledge bases that can become outdated, leading LLMs to hallucinate or give wrong info on dynamic topics like financial markets or weather.
How does Smart RAG improve on standard RAG?
Smart RAG adds live external data sources through APIs, allowing systems to provide current and accurate responses instead of depending on old pre-indexed information.
What are APILayer’s Marketstack and Weatherstack APIs?
Marketstack offers real-time and historical stock data from global exchanges, while Weatherstack provides current, historical, and forecast weather info for locations worldwide, both accessible via simple REST endpoints.
What are the main components in a Smart RAG system architecture?
Key components include a query processor to parse inputs, data pipelines for fetching and embedding info, the RAG core for retrieval and generation, AI agents for multi-step tasks, and backend infrastructure on MCP servers for scaling.
How do data pipelines work in real-time API integration for RAG System?
Data pipelines trigger from parsed user queries, fetch data via conditional API calls, process and embed it into vector databases like Pinecone, and handle updates with webhooks or polling for ongoing freshness.